Local PII Extractor:個資識別與匿名化工具
GitHub Repo
個資提取與替換工具使用 spaCy NER + 正規表示式完成雙重偵測,並提供簡潔 GUI 操作介面。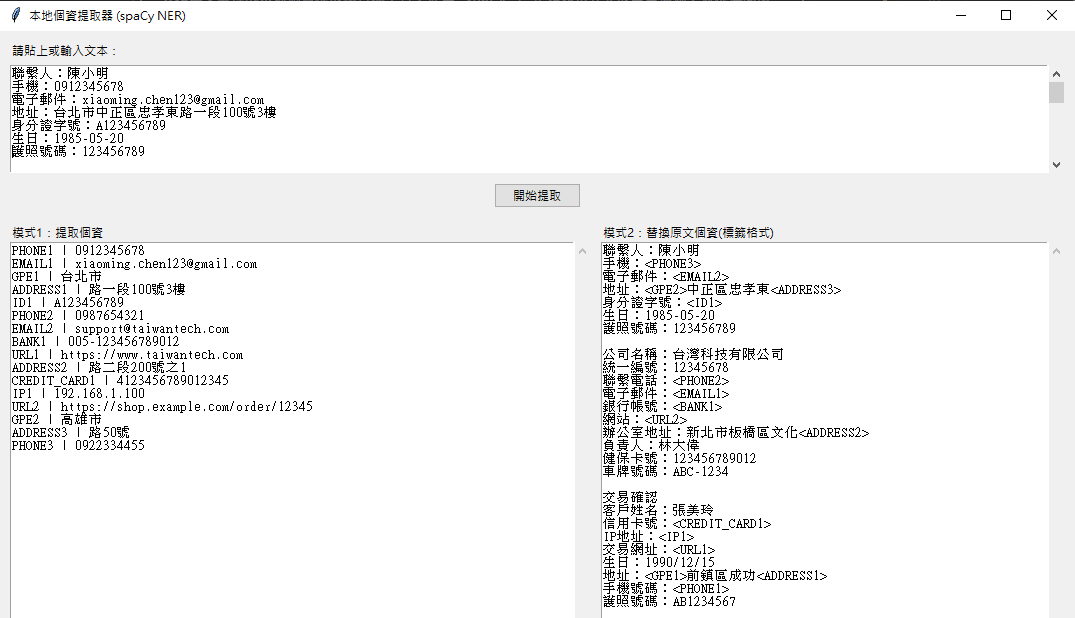
簡介
許多使用者習慣將資料輸入至如 GPT, Grok或Claude等AI模型進行處理,但這些資料可能包含機敏資訊(例如電話號碼、身分證號、信用卡資訊等),直接上傳可能面臨個資外洩的風險。
那我就想到,如果能在上傳資料到這些大語言模型之前,先在本地自動把重要資料先移除 (手動的話會很久很麻煩),避免資料偷偷被這些公司拿去蒐集訓練,造成個資外洩,所以就結合自己在自然語言處理領域的研究,使用NER的方式去實作。
開發 Local PII Extractor,支援中文的本地個資提取與匿名化工具,使用spaCy與正規表示式進行雙重偵測,並提供簡潔的 GUI 操作介面,讓使用者能夠在本地環境中安全地處理敏感資料。
架構
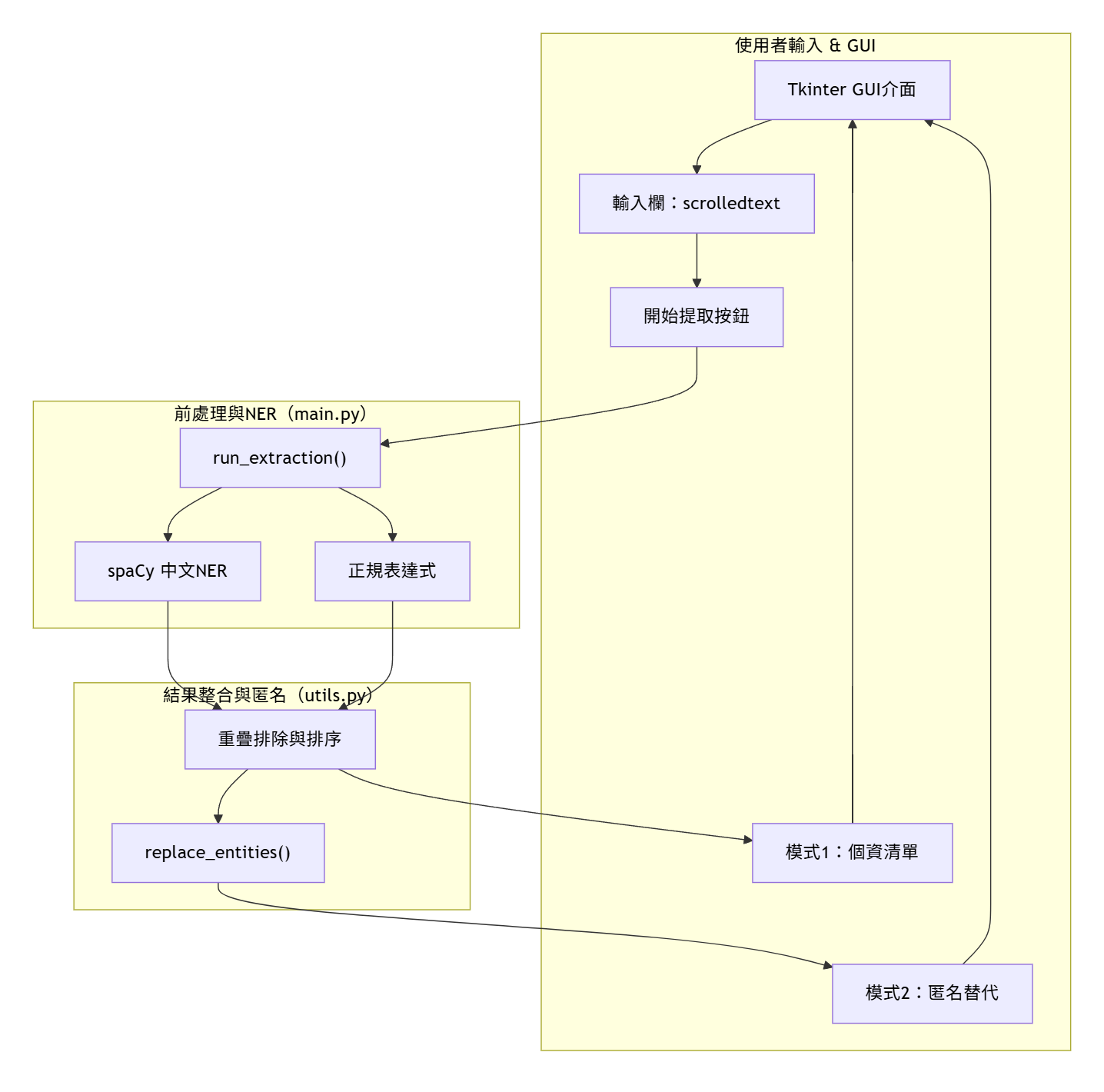
動機
- 資料安全性:避免將包含敏感資訊的資料上傳至雲端,降低資料外洩風險。
- 支援中文處理:現有的 PII 工具多以英文為主,缺乏對中文的良好支援。
- 易於使用:透過 GUI 介面,讓非技術背景的使用者也能輕鬆操作。
功能
- 雙重偵測機制:結合 spaCy 的自然語言處理能力與正規表示式,提升個資識別的準確性。
- 支援多種個資類型:能夠識別並處理電話號碼、身分證號、信用卡資訊等常見的敏感資訊。
- 本地處理:所有資料處理皆在本地進行,無需連接網路,保障資料隱私。
- GUI 操作介面:提供直觀的圖形介面,方便使用者進行資料上傳、處理與下載。
技術
程式語言:Python
主要套件:
- spaCy:用於自然語言處理與實體識別(NER)。
re(正規表示式):輔助識別特定格式的敏感資訊。tkinter:建立 GUI 操作介面。
使用說明
安裝依賴套件:
1
pip install -r requirements.txt
啟動應用程式:
1
python main.py
操作流程:
- 啟動後,會出現 GUI 介面。
- 點選「選擇檔案」上傳欲處理的文本檔案。
- 點選「開始處理」,系統將自動識別並匿名化敏感資訊。
- 處理完成後,點選「下載結果」取得處理後的檔案。
專案結構
1 | Local_PII_Extractor/ |
未來規劃
- 支援更多語言:擴展對其他語言(如日文、韓文等)的支援。
- 提升識別準確率:引入更先進的 NLP 模型,提升個資識別的準確性。
- 增加批次處理功能:允許使用者一次處理多個檔案,提高效率。